Power BI, y otros productos de BI de nueva generación, ha incorporado al Business Intelligence perfiles de creadores de informes que no hace mucho era imposible que pudieran hacerlo. Muchos de ellos son grandes conocedores de Excel y han encontrado en Power BI una forma natural de transmitir los datos que manejan.
Antes, solo profesionales de marcado perfil técnico en bases de datos y de la herramienta de turno de BI eran capaces de transformar grandes volúmenes de datos en informes rápidos de ejecutar y entender. Ahora, con estas herramientas el segmento que se aventura a crear proyectos de BI se ha ampliado.
Pero una cosa es crear un conjunto de datos pequeño de uso individual y otra muy distinta es la de crear uno con cierta amplitud, complejidad y volumen que tengan que utilizar otros. La capa semántica, al margen de su aspecto más técnico viene a facilitar es uso compartido con normas bastante simples.
La importancia de la capa semántica
Cuando un usuario se enfrenta a un conjunto de datos para realizar un informe primero tiene que comprender qué es lo que contiene esa capa de datos, muchas veces nos encontramos con medidas dispersas con nombres parecidos que parecen apuntar el mismo dato y es habitual que aparezca la confusión y hasta el rechazo y miedo a enfrentarse a los datos.
Una capa semántica es la que comunica los datos con el usuario y sirve exactamente para asegurarse que los usuarios comprenderán fácilmente los datos que maneja encontrando sin ambiguedades aquellas medidas y campos que necesitan. La capa semántica abarca la organización de las medidas, tablas de hechos, dimensiones, jerarquías, la denominación de cada uno de los objetos y también su documentación de una manera que cualquier usuario de negocio comprenda los datos que tiene delante. Aunque la capa semántica se extiende en el plano técnico, con la abstracción de los diferentes orígenes de datos y su organización, nos centraremos en las características que van a facilitar las cosas al usuario final.
Diseñando el modelo de datos
Cuando partimos de una tabla de hechos (por ejemplo, la facturación de una empresa) tendemos a pensar en el plano técnico, de eficiencia, aunque por el camino del diseño del modelo de datos es posible que surjan dudas, y la solución debe ser, aunque sea la más compleja técnicamente, la que mayor aceptación pensemos que vaya a tener en el usuario final.
Podemos tener escenarios del tipo: necesitamos la facturación trimestral. La decisión técnica puede ser variada. Podemos tener una medida llamada “Facturación trimestral” o bien obligar al usuario a escoger la medida “Facturación” y el periodo “Trimestre” para obtener el mismo resultado. No hay una respuesta válida general, dos conjuntos de datos pueden tener una decisión válida distinta. Dependerá de varios factores: la cultura de la empresa, el tipo de usuario final o la extensión del modelo de datos.
Reuniendo la información necesaria
Un datawarehouse es aquel almacen de datos que reúne toda la información de la empresa en un único lugar y la expone a herramientas como Power BI. En ocasiones es necesario disponer de herramientas intermedias, como Analysis Services, pero dependiendo del volumen este paso intermedio lo podemos obviar y trabajar directamente con Power BI.
Pero muchos proyectos con Power BI no parten de un datawarehouse, simplemente recogen datos directamente de las fuentes trasaccionales (CRM, ERP, programas contables, de Recursos Humanos, etc) y con ellos se crean conjuntos de datos que contienen una visión de la organización con datos departamentales (contables, comerciales, etc.). Este es uno de los pasos más importantes a estudiar pues debemos asegurarnos que el usuario final podrá disponer de toda la información necesaria.
Si estamos pensando en un conjunto de informes destinado al área comercial, debemos pensar en su información importante y entender de donde la debemos recuperar. En ocasiones esto implica importar datos del CRM para disponer de la actividad sobre clientes, del ERP para contabilizar ventas y puede que de uno o varios archivos de Excel para obtener los objetivos de venta y otras informaciones.
Si pensamos que el usuario final, tomará la herramienta como guía para su negocio, debemos asegurarnos que dispondrá de toda la información y que los informes no quedarán cojos..
Estandarizando el nombre de las cosas. Nombres claros
Lo habitual en el modelo transaccional es encontrarnos con campos del tipo ID, COD_Prod y otras abreviaciones. En el modelo que construyamos en Power BI debemos seguir un patrón en la denoinación de las tablas y campos y deben ser lo más descriptivas posibles, de esta manera si es necesario que el usuario maneje el código de producto, debemos denominarlo de forma natural “Código de producto”.
También lo más lógico es que si debemos mostrar otros códigos, estos se denominen “Código de …”. En ocasiones nos encontraremos con dudas y puede que estemos tentados a escribir “Producto código” para favorecer la ordenación de los objetos, esto no suele funcionar. Mejor hacerlo con lenguaje natural aunque sea necesario a veces eliminar conjunciones.
DocumentandO: no pueden quedar dudas
Por norma general debemos escribir descripciones de todas las medidas. Si es necesario, también de los campos de las tablas. Power BI dispone de un método sencillo para hacerlo, cada elemento de la lista de campos tiene sus propiedades y podemos acceder a ellas mediante el menú contextual (click botón secundario, Propiedades) o bien desde el menú superior (vista, Propiedades de campo).
Esto nos permite modificar el nombre pero también añadir una descripción.
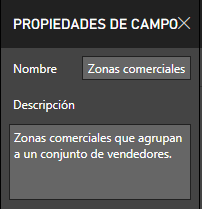
El usuario final se aprevechará de esta descripción cuando situe el ratón encima del campo o tabla con un tooltip:

También es muy recomendable comentar todas las funciones de Power Query que se utilicen. Otras personas pueden utilizarlas en un futuro y deberían disponer fácilmente de un texto que respondiera a sus dudas.
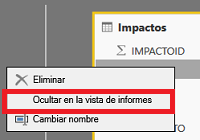
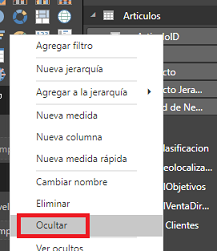
Escondiendo cosas
En los orígenes de datos probablemente las tablas contienen muchas columnas innecesarias, con Power Query las podemos eliminar. Otras serán necesarias para ciertos cálculos pero el usuario final no necesitará utilizarlas, entonces deberemos esconder la tabla/campo/medida para que no aporte confusión.
Esto lo podemos hacer desde el editor de relaciones o bien desde la lista de campos
Cuando escribamos funciones DAX de cierta complejidad es posible que necesitemos medidas intermedias, muchos de estos cálculos sirven para la fórmula actual y no van a ser necesarios en otras funciones. Aqui es cuando debemos aprovecharnos de la capacidad de DAX para trabajar con variables.
En este post podéis ver una medida con un código bastante extenso que hace uso de las variables. La documentación de Microsoft no es muy extensa en este apartado pero define su utilización. También podéis echar un vistado a este otro artículo de sqlbi.
Agrupando medidas
Dependiendo de las circunstancias es posible que sea mejor para el usuario final disponer de todas las medidas en una misma carpeta. Es una decisión que es necesario, por conveniencia, realizar al inicio del proyecto. En un artículo anterior hablamos de como hacerlo.

Eficiencia
Power BI tiene de tres caras: la importación y transformación de datos (Power Query) y Power BI en sí que permite la creación de medidas y jerarquías y el Power BI donde creamos los informes.
Todas las acciones que podamos realizar en Power Query van a contribuir a un mejor desempeño de Power BI. Esto es muy importante y solo se ve el impacto a partir de un cierto volumen y complejidad de datos. Cuando manejamos pocos datos y tablas el sistema funciona correctamente pero a partir de cierto momento y de forma exponencial las cosas se pueden/suelen torcer si el diseño no es eficiente.
Por ello, aunque sea el cambio de nombre de ciertas columnas o tablas lo haremos en Power Query. Si necesitamos de una columna y lo podemos hacer en Power Query, mucho mejor, si podemos resolver algún dato con una función de Power Query, evitaremos cálculos innecesarios en cada petición de un informe.
Aspectos técnicos
Dejo para otro día ciertos aspectos técnicos, muy importantes en el momento de diseñar el conjunto de datos. Perseguir, siempre que sea posible, un modelo en estrella y como conseguirlo con unos pocos trucos en Power Query nos ayudará también a disponer de ese modelo semántico ideal que hará que los usuarios vean un modelo entendible, rápido de comprender y de manejar.
Lista de cosas a comprobar
En diciembre pasado SQL Chick publicó una lista de aspectos a tener en cuenta, a modo de checklist, en el momento del diseño de un modelo de datos con Power BI. Se trata de una lista donde figura la tarea a revisar, el motivo de tener que hacerlo y el modo como lo podemos hacer, sin duda es de obligada lectura.